Appearance
平台简介
什么是在鸿云AI平台
在鸿云AI平台是在鸿云团队在AI领域的探索研究成果,目前包含四大模块:
- 1、基于AI-AGENT开源框架打造的混合AI
- 2、基于大语言模型ChatGLM进行训练改造的对话模型
- 3、基于PaddleSpeech开源框架打造的AI语音模块
- 4、基于目标检测模型YOLO打造的混合AI
工作原理
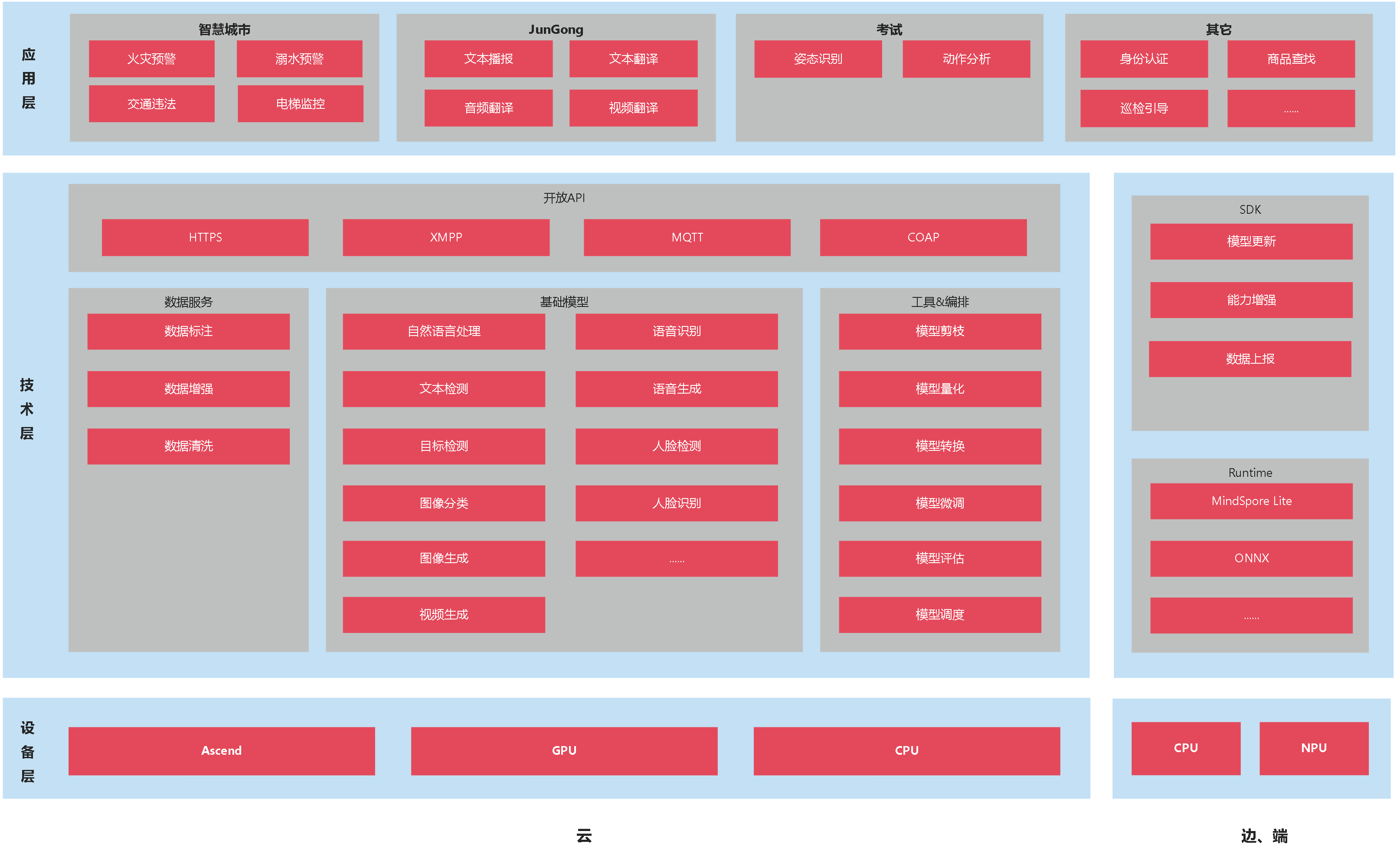
AI平台应用架构如下图:
ZAIHOS-AGENT 整体架构如下图:
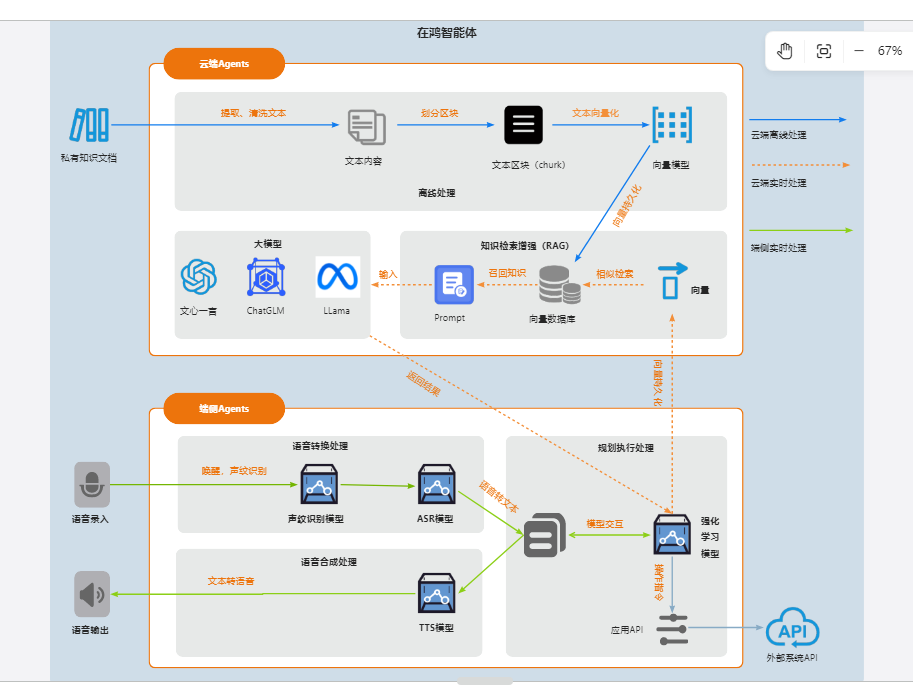
ZAIHOS-AGENT介绍
ZAIHOS-AGENT是一个通用的、可定制的Agent框架,用于实际应用程序,其基于开源的大语言模型 (LLMs) 作为核心。它提供了一个用户友好的系统库, 具有以下特点: 可定制且功能全面的框架:提供可定制的引擎设计,涵盖了数据收集、工具检索、工具注册、存储管理、定制模型训练和实际应用等功能,可用于快速实现实际场景中的应用。 开源LLMs作为核心组件:多样化且全面的API:以统一的方式实现与模型API和常见的功能API的无缝集成。
CHATGML-6B介绍
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答
PaddleSpeech介绍
PaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型
YOLO目标检测介绍
YOLO(You Only Look Once)是一种实时目标检测算法,它可以在单次前向传递中同时检测出图像中的多个目标。该算法最初由 Joseph Redmon 等人于2016年提出,并在许多计算机视觉竞赛中获得了优异的成绩。 YOLO的目标是实现快速、准确和高效的目标检测,它采用了深度卷积神经网络(CNN) 的结构,将整个图像分成若干个网格,每个网格都预测一个边界框和类别概率分布。具体来说,YOLO将输入的图像分成SxS个网格,每个网格的大小为SxS像素,然后在每个网格内使用13x13大小的卷积核进行特征提取。接下来,YOLO使用两个全连接层来预测每个网格内的边界框和类别概率分布。最终,YOLO将所有网格的结果合并起来,得到整个图像的检测结果。 由于YOLO使用了高效的卷积神经网络结构和并行计算技术,因此它的检测速度非常快,可以达到每秒处理数千张图像的速度。此外,YOLO还具有较高的准确性和鲁棒性,可以在不同的场景和光照条件下进行目标检测。
关键技术
- 云侧RAG工程
- 端侧模型压缩
- 异构模型迁移
- 强化学习模型(AI Agents)
名词解释
| 术语 / 缩略词 | 说明 |
|---|---|
| AI平台 | 提供人工智能服务如:混合AI、语音、目标检测、对话等服务 |
| ASR | 语音识别 |
| TTS | 语音合成 |
| CV | 计算机视觉 |
| LLM | 大语言模型 |